<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
Ein XSLT Style Sheet ist formal eine wohlgeformte XML-Datei mit der Deklaration eines Namensraums (xmlns, mit dem Kürzel "xsl"), der auf "http://www.w3.org/1999/XSL/Transform" verweist. Das Kürzel "xsl" ist im Grunde beliebig, wird aber meistens so verwendet. In der Style Sheet Datei bedeuten alle XML-Elemente, die zu diesem Namensraum gehören, daß diese Elemente als Befehle interpretiert werden, die der sogenannte XSLT-Prozessor (das Programm mittels dieses Style Sheets eine gegebene XML-Quelldatei umwandelt) verarbeitet. Alle anderen Tags (in diesem Fall die bekannten HTML-Tags) werden im Verarbeitungsablauf unverändert an die Ausgabe weitergeleitet.
<xsl:output method="html"/>
Hier wird die Ausgabemethode festgelegt. Die Ausgabemethode bestimmt im wesentlichen die Art und Weise, wie Zeichen geschrieben werden, bei "html" wird also zum Beispiel aus den Umlauten (ÄÖÜ) ÄÖÜ .
<xsl:template match='/'> <html> <head> <title> <xsl:value-of select="/abschnitt/ueberschrift/text()"/> </title> </head> <body> <xsl:apply-templates select="*"/> </body> </html> </xsl:template>
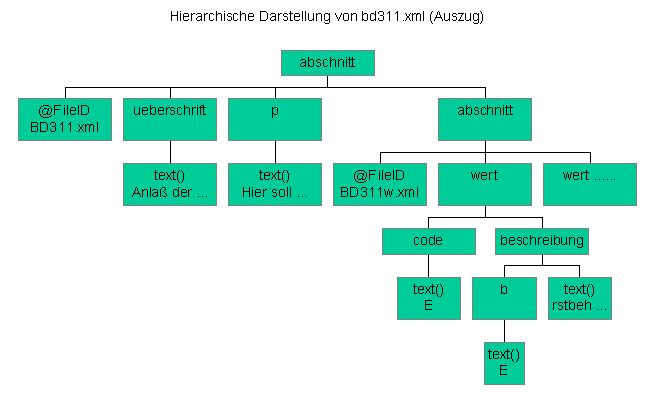
Templates sind an oberster Stelle unter dem Stylesheet-Element angesiedelt. Sie bestimmen anhand des match-Attributs, auf welche Bestandteile des XML-Dokuments die in das Element eingeschlossenen Unterbestandteile angewendet werden sollen. Für das Verständnis der Verarbeitung ist es wichtig, sich das XML-Quelldokument als "Baum" (bd311.png) vorzustellen, mit dem Dokument-Element als Stamm-Wurzel und den Unterelementen und deren Unterelementen bzw. Textinhalten als Verzweigungen des Wurzelwerkes. In obigem Template kann man sich das so vorstellen:
<xsl:template match="abschnitt"> <xsl:apply-templates select="*"/> </xsl:template>
Auf jeden Elementknoten abschnitt wird lediglich die Anweisung ausgeführt, daß wiederum direkte Unterelemente herausgesucht werden. In diesem Fall ueberschrift, p und abschnitt.
<xsl:template match="ueberschrift"> <h1> <xsl:apply-templates select="*|text()"/> </h1> </xsl:template>
Ein Elementknoten ueberschrift wird mit HTML-h1 getaggt. Zwischen Start- und Ende-Tag werden direkte Unterelemente und Textknoten herausgesucht.
<xsl:template match="text()"> <xsl:value-of select="."/> </xsl:template>
Textknoten werden mit der value-of-Anweisung direkt dargestellt..
<xsl:template match="/abschnitt/abschnitt[@FileID='BD311w.xml']"> <table> <xsl:apply-templates select="wert"> <xsl:sort select="code"/> </xsl:apply-templates> </table> </xsl:template>
Dieses Template paßt nur auf Abschnitte, die unter einem Abschnitt liegen, der unter dem Wurzelknoten liegt und das Attribut FileID mit dem Wert BD311w.xml besitzen. In diesem Fall werden die Unterelemente wert und zwar sortiert nach deren Unterelement code herausgesucht. Außerdem wird alles, was bei apply-templates gefunden wird, in eine HTML-Tabelle gepackt.Hinweis: Natürlich hätte auch das allgemeinere Template weiter oben gepaßt. Eingebaute Regeln sorgen dafür, daß im allgemeinen das spezifischste Template genutzt wird. Für Zweifelsfälle gibt es ein priority-Attribut.
<xsl:template match="wert"> <tr> <td> <xsl:apply-templates select="code/*|code/text()"/> </td> <td>=</td> <td> <xsl:apply-templates select="beschreibung/*|beschreibung/text()"/> </td> </tr> </xsl:template>
Dieses Template erstellt für die gefundenen Werte die eigentliche Tabellenreihen. In der ersten Spalte werden Unterelemente des Unterelements Code und Textknoten des Unterelements Code herausgesucht. In der zweiten Spalte passiert das gleiche für die Beschreibungen.
<xsl:template match="p|b"> <xsl:copy> <xsl:apply-templates select="*|text()"/> </xsl:copy> </xsl:template> </xsl:stylesheet>
Elemente, mit dem Namen p oder b werden einfach in die Ausgabe kopiert und dann werden alle Unterelemente und Textknoten herausgesucht.
Merke: XSLT ist eine deklarative Sprache in der auf bestimmte
Muster (Templates) Anweisungen ausgeführt werden. Deklarative Sprachen
zeichnen sich gegenüber prozeduralen dadurch aus, daß sie nicht
unbedingt durch Kontrollanweisungen (IF, WHILE, FOR ....) vorgeben, wie
genau eine Verarbeitung zu erfolgen hat, sondern im wesentlichen nur beschreiben,
was gemacht werden soll. Möchte man das gleiche wie oben mit einer
prozeduralen Sprache (Java, Perl, C, ...) erreichen, wäre das ungleich
aufwendiger. Auch für diesen Zweck gibt es einen WWW-Standard, das
Document Object Model (DOM).
Für das Verständnis von XPath sind zunächst drei Grundbegriffe notwendig:
| Bezeichnung | Beispiel | Ergebnisknoten
Typ:evtl Name, evtl. Inhalt |
| child | alle Kindknoten des ersten beschreibung Elements |
|
| descendant | alle Nachkommen des ersten wert Elements |
|
| parent | Eltern des ersten wert Elements |
|
| ancestor | alle Ahnen des ersten wert Elements |
|
| following-sibling | alle folgenden Knoten mit den gleichen Eltern für ueberschrift |
|
| preceding-sibling | alle vorhergehenden Knoten mit den gleichen Eltern für abschnitt
Merke: "Die Eltern von Attributknoten sind zwar Elemente, Attributknoten aber keine Kinder von Eltern" |
|
| following | alle nachfolgenden Knoten im Dokument ohne die, die Nachkommen sind,
des ersten code Elements
(siehe vollständiges Dokument bd311.xml) |
|
| preceding | alle vorhergehenden Knoten im Dokument ohne die, die Ahnen sind, des abschnitt Elements |
|
| attribute | alle Attributknoten des ersten abschnitt Elements |
|
| namespace | die Namespace-Knoten des Knotens (nur bei Elementen) (nicht in der Testumgebung implementiert) | |
| self | der Knoten selbst, z.B. das abschnitt Element |
|
| descendant-or-self | der Knoten selbst und seine Nachkommen, z.B. das ueberschrift Element |
|
| ancestor-or-self | der Knoten selbst und seine Ahnen, z.B. das ueberschrift Element |
|
| Bezeichnung | zugehörige Testfunktion | Beschreibung |
| Wurzelknoten | "/" | Der Wurzelknoten ist eine fiktive Struktur des XML-Dokuments und nicht
mit dem Wurzelelement zu verwechseln. Das Wurzelelement selbst ist ein
Kind des Wurzelknotens; vor dem Wurzelelement könnten aber zum Beispiel
auch Processing-instructions stehen, die ebenfalls Kinder des Wurzelknotens
sein können.
Der Wurzelknoten hat keinen Namen. Der Textinhalt ist die Menge aller Textknoten die Nachfahren sind. |
| Elementknoten | Name eines gesuchten Elements oder "*" | Elementknoten können folgende Kinder haben:
|
| Textknoten | text() | Textknoten repräsentieren den Textinhalt von Tags, einschließlich von CDATA-Abschnitten. CDATA-Abschnitte werden also nicht als extra Knotentyp geführt, sondern vor der Verarbeitung "expandiert", was auch für Entity-Referenzen zutrifft. |
| Attributknoten | Attributknoten sind keine Kinder ihrer Elemente (sie haben ja zum Beispiel
auch keine definierte Reihenfolge, jedes Attribut kann auch nur einmal
pro Element vorkommen). Ihre Elemente werden aber als ihre Eltern betrachtet.
Auf Name und Inhalt des Attributs kann zugegriffen werden. |
|
| Namensraumknoten | Namensraumknoten sind Elementen zugeordnet, aber keine Kinder ihrer Elemente. Ihre Elemente werden aber als ihre Eltern betrachtet. Für alle Namensräume, die im Element oder in Attributen des Elements oder seiner Ahnen verwendet werden, gibt es Namespace-Knoten. Sie enthalten Informationen über das verwendete Kürzel und die zugehörige URL. | |
| Kommentarknoten | comment() | Bei Kommentarknoten kann auf den Kommentartext zugegriffen werden. |
| Verarbeitungsanweisungsknoten (Processing-instruction) | processing-instruction() | Hier kann auf das Ziel und den Text der Verarbeitungsanweisung zugegriffen werden. |
Mit den Konstrukten Knoten und Achsen können bereits erste XPath
Ausdrücke ausprobiert werden. Prädikate sind nicht unbedingt
notwendig und werden zur Übersichtlichkeit erst später erläutert.
XPath-Ausdrücke (Location Path) werden aus sogenannten Location
Steps zusammengesetzt. Jeder Location Step besteht aus einer Achse, einem
Knoten und, optional einem Prädikat. Location Steps werden durch "/"
voneinander getrennt. Entsprechend Dateisystemen gibt es absolute Pfadangaben,
beginnend mit "/" (dem Wurzelknoten) und relative Pfade, die relativ zum
akuellen Knoten (dem Kontext-Knoten) gesehen werden.
Für häufig verwendete Achsen/Knoten gibt es Abkürzungen,
die die Pfadangaben denen eines UNIX-Dateisystems ähneln lassen.
| child:: | (vorgegebene Achse, kann weggelassen werden) |
| attribute:: | @ |
| /descendant-or-self::node()/ | //
node() umfaßt alle o.g. Knotentypen, die durch Knotentests angesprochen werden können, also Wurzel-, Element, Text-, Kommentar- und Verarbeitunsganweisungknoten |
| self::node() | . |
| parent::node() | .. |
| XPath-Ausdruck | XML-Datei | Ergebnis |
| /child::abschnitt/child::ueberschrift/child::text()
Abgekürzte Form: /abschnitt/ueberschrift/text() |
bd311.xml |
|
| descendant-or-self::processing-instruction()
Abgekürzte Form: //processing-instruction() |
bd5.xml |
|
| /child::abschnitt/child::abschnitt/attribute::FileID
Abgekürzte Form: /abschnitt/abschnitt/@FileID |
bd5.xml |
|
| /child::abschnitt/child::abschnitt/attribute::FileID/parent::*
Abgekürzte Form: /abschnitt/abschnitt/@FileID/../* |
bd311.xml |
|
| /self::node()/*
/./* |
bd311.xml |
|
| /child::abschnitt/child::abschnitt/descendant-or-self::node()/text()
Abgekürzte Form: /abschnitt/abschnitt//text() |
bd311.xml |
|
Achse::Knoten[Prädikate]Ein Prädikat besteht aus einer oder mehrerer verknüpfter Bedingungen, die auf die zunächst erhaltene Ergebnismenge angewendet werden. Wenn die Bedingungen den Wahrheitswert "WAHR" zurückgeben, wird das Element der Ergebnismenge ausgewählt. XPath stellt dafür eine Reihe von Funktionen bereit, von denen im folgenden nur einige beispielhaft gezeigt werden.
| XPath | Beschreibung | Ergebnis |
| //wert[position() = 1]/code/text()
Abgekürzte Form: //wert[1]/code/text() |
Den Code des ersten wert Elements. Position gibt die Folgenummer des Knotens in der Ergebnismenge an. Weil position()-Abfragen relativ häufig benötigt werden, existiert die angegebene abgekürzte Form. |
|
| //wert[code/text()='L']/beschreibung//text() | Die Textknoten von beschreibung von wert, bei dem der Textknoten von code = 'L' ist. |
|
| //text()[starts-with(.,'N')] | Textknoten, die mit N anfangen. |
|
| //text()[contains(., 'st')] | Textknoten, die st enthalten. |
|
| //text()[substring(., 3, 2)= 'gn'] | Textknoten mit der Zeichenkette gn an dritter Stelle. |
|
| //*[last()=3] | Elementknoten, die Teil einer Menge der Anzahl 3 sind |
|
| //*[count(child::text())=2]/text() | Textknoten von Elementknoten, die genau zwei Textknoten als Kinder haben |
|
| //abschnitt[@FileID="BD284.xml"]//ueberschrift[substring(text(), 1, 6) = 'Quelle']/descendant-or-self::node() | in bd5.xml Alle Knoten absteigend vom ueberschrift Knoten, bei denen die ersten Buchstaben des Texts der Überschrift 'Quelle' sind und die als Vorfahr einen abschnitt Knoten mit der FileID 'BD284.xml' besitzen. |
|
| //abschnitt[@FileID="BD284.xml" or @FileID="BD868.xml"]//ueberschrift[substring(text(), 1, 6) = 'Quelle']/descendant-or-self::node() | Das gleiche, aber jetzt mit einer ODER-Verknüpfung |
|
Auf die Datei bd311.xml angewandt liefert es folgende Ausgabe:<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> </xsl:stylesheet>
Anlaß der Erfassung von DiagnosedatenHier soll erfaßt werden, in welcher Phase der Betreuung bzw. mit welchem Ziel der Patient im Zentrum aufgenommen worden ist. Bei jeder Behandlung und Betreuung werden in gewissem Umfang diagnostische Maßnahmen durchgeführt. Diagnostische Maßnahmen sind deshalb bei den Kürzeln "E" und "W" enthalten. Die Merkmalsausprägung "D" (Diagnostik) bedeutet, daß innerhalb des Zentrums nur die Diagnostik durchgeführt wurde und der Patient zur Weiterbehandlung in eine andere Klinik verlegt worden ist.EErstbehandlungWWeiterbehandlungLNachsorge / LangzeitbetreuungDNur DiagnostikXUnbekanntAnmerkung:
Offensichtlich wurden einfach alle Textknoten des Dokuments in der richtigen Reihenfolge ausgegeben. Das liegt daran, daß in jedem Stylesheet einige Templates und dazugehörige Verarbeitungsregeln als vorhanden angenommen werden.
<xsl:template match="*|/"> <xsl:apply-templates/> </xsl:template>
<xsl:template match="text()|@*"> <xsl:value-of select="."/> </xsl:template>
<xsl:template match="processing-instruction()|comment()"/>
<xsl:template match="*|/" mode="m"> <xsl:apply-templates mode="m"/> </xsl:template>Sie entspricht der obigen ersten Regel weitgehend und tritt dann in Kraft, wenn mit Modi gearbeitet wird. Modi dienen dazu, gleiche Knotenmengen für unterschiedliche Zwecke mehrfach zu bearbeiten, z.B. Überschriften einmal für das Inhaltsverzeichnis und einmal für den Volltext.
Es ist wichtig, diese eingebauten Regeln zu verstehen. Zum einen ersparen sie für häufige Fälle Tiparbeit (in der Regel möchte man ja Textknoten in der ausgabe haben, da diese die Information tragen), zum anderen können sie gelegentlich auch unerwünschte Nebeneffekte verursachen. In diesem Fall sollte man sie mit einer eigenen Regel "überschreiben". Die selbst definierten Regeln haben immer eine höhere Priorität.
Als Beispiel XML-Dateien dienen die bekannten bd5.xml
und bd311.xml. Die Style Sheet Dateien erstellen
Sie selbst, indem Sie im gleichen Verzeichnis neue Dateien, am besten mit
der Endung "xsl" erzeugen (z.B. über kopieren und umbenennen) und
mit dem Notepad bearbeiten.
Für die folgenden Übungen wird die Quelldatei bd5.xml
benötigt.
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:output method='xml'/>
<xsl:template match='/'>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match='*'>
<xsl:element name="{name()}">
<xsl:for-each select="@*">
<xsl:attribute name="{name()}">
<xsl:value-of select='.'/>
</xsl:attribute>
</xsl:for-each><xsl:apply-templates/>
</xsl:element>
</xsl:template>
<xsl:template match='text()'>
<xsl:value-of select='.'/>
</xsl:template>
<xsl:template match='comment()'>
<xsl:comment>
<xsl:value-of select='.'/>
</xsl:comment>
</xsl:template>
<xsl:template match='processing-instruction()'>
<xsl:processing-instruction name="{name()}">
<xsl:value-of select='.'/>
</xsl:processing-instruction>
</xsl:template>
</xsl:stylesheet>
Erläuterungen:
An dieser Stelle muß auf eine noch einfachere Methode verweisen werden, XML-Dokumente oder Teile davon zu kopieren. Das gleiche Ergebnis hätte auch folgendermaßen erzielt werden können:
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method='xml'/> <xsl:template match='/'> <xsl:apply-templates/> </xsl:template> <xsl:template match="@*|*|text()|comment()|processing-instruction()"> <xsl:copy> <xsl:apply-templates select="@*|node()"/> </xsl:copy> </xsl:template> </xsl:stylesheet>"copy" erzeugt Kopien von einzelnen Knoten anstatt sie explizit mit knotenspezifischen Anweisungen zu erzeugen. Dazu gibt es noch die Anweisung "copy-of", die ganze Dokumentfragmente kopiert, z.B.:
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method='xml'/> <xsl:template match='/'> <xsl:copy-of select="."/> </xsl:template> </xsl:stylesheet>
<root_node> <comment> Nichtssagender Kommentar 0</comment> <pi name="pi0" wert="Nichtssagende Verarbeitungsanweisung0 "/> <element name="abschnitt"> <attribut name="FileID" wert="BD5.xml"/> <text>Basisdokumentation für Tumorkranke, 5. Auflage</text>
<xsl:template match="/abschnitt/abschnitt[@FileID='BD311w.xml']"> <table> <xsl:apply-templates select="wert"> <xsl:sort select="code"/> </xsl:apply-templates> </table> </xsl:template>Wenn man das select Attribut in sort wegläßt, wird der Wert des aktuellen Knotens benutzt. Für das Sortieren gibt es eine Reihe weiterer Attribute, mit denen sich Sortierkriterien und Ordnung weiter spezifizieren lassen, siehe Standard.
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:output method='html'/>
<xsl:template match='/'>
<html>
<xsl:apply-templates/>
</html>
</xsl:template>
<xsl:template match='abschnitt'>
<xsl:param name='l' select="1"/>
<!--Das Select-Attribut für Parameter-Variablen gibt den Vorgabewert an-->
<xsl:apply-templates select='ueberschrift'>
<xsl:with-param name='l'>
<xsl:value-of select="$l"/>
</xsl:with-param>
</xsl:apply-templates>
<xsl:apply-templates select='abschnitt'>
<xsl:with-param name='l'>
<xsl:value-of select="$l +1 "/>
</xsl:with-param>
</xsl:apply-templates>
</xsl:template>
<xsl:template match='ueberschrift'>
<xsl:param name='l' select="0"/>
<xsl:variable name='u'>
<xsl:value-of select="text()"/>
<xsl:comment>Dies ist ein Beispiel, wie eine Variable ein Dokumentfragment enthält</xsl:comment>
</xsl:variable>
<xsl:element name="{concat('h',$l)}">
<!-- concat "klebt" Zeichenketten -->
<xsl:copy-of select="$u"/>
</xsl:element>
</xsl:template>
<xsl:template match='*'>
<!--nichts tun-->
</xsl:template>
</xsl:stylesheet>
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method='html'/> <xsl:template match='/'> <html><body> <xsl:apply-templates/> </body></html> </xsl:template> <xsl:template match='*'> <xsl:choose> <xsl:when test="name()='abschnitt'"> <xsl:if test="contains(@FileID, 'w')"> <xsl:element name="table"> <xsl:apply-templates/> </xsl:element> </xsl:if> <xsl:if test="not(contains(@FileID, 'w'))"> <xsl:apply-templates/> </xsl:if> </xsl:when> <xsl:when test="name()='ueberschrift'"> <xsl:element name="h1"> <xsl:apply-templates/> </xsl:element> </xsl:when> <xsl:when test="name()='wert'"> <xsl:element name="tr"> <xsl:apply-templates/> </xsl:element> </xsl:when> <xsl:when test="(name()='code') or (name()='beschreibung' )"> <xsl:element name="td"> <xsl:apply-templates/> </xsl:element> </xsl:when> <xsl:otherwise> <xsl:copy-of select="."/> </xsl:otherwise> </xsl:choose> </xsl:template> </xsl:stylesheet>
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method='html'/> <xsl:template match='/'> <html> <xsl:apply-templates mode="ueberschrift" select="abschnitt/abschnitt[not(contains(@FileID, 'w'))]"/> <xsl:apply-templates mode="volltext" select="abschnitt/abschnitt[not(contains(@FileID, 'w'))]"/> </html> </xsl:template> <xsl:template match='abschnitt' mode="ueberschrift"> <xsl:element name="a"> <xsl:attribute name="href"> #<xsl:value-of select="@FileID"/> </xsl:attribute> <xsl:value-of select="ueberschrift/text()"/> </xsl:element> <xsl:apply-templates mode="ueberschrift" select="*[name()='abschnitt' and not(contains(@FileID, 'w'))]" /> <br/> </xsl:template> <xsl:template match='abschnitt' mode="volltext"> <xsl:element name="a"> <xsl:attribute name="name"> <xsl:value-of select="@FileID"/> </xsl:attribute> <xsl:value-of select="ueberschrift/text()"/> </xsl:element> <xsl:apply-templates mode="volltext" select="*[name()='abschnitt' and not(contains(@FileID, 'w'))]" /> <br/> </xsl:template> </xsl:stylesheet>