Daten in Tabellen laden
Mit dem Java-Programm "TabLoad" können Daten aus Dateien in Tabellen geladen werden. Dazu sind die Java-Klassen des WebGTDS erforderlich. Obwohl theoretisch beliebige Tabellen gefüllt werden könnten, ist das Programm primär dazu gedacht, die IMPORT- und EXTERNE-Tabellen zu füllen. Bei allen übrigen GTDS-Tabellen besteht das Risiko, daß wichtige Bedingungen nicht berücksichtigt werden, deren Nichtbeachtung zu einer Zerstörung von Daten führen können! Auch bei den IMPORT- und EXTERNE-Tabellen ist eine Kenntnis der Zusammenhänge erforderlich (siehe import.htm) Das Programm benötigt zwei Eingabeparameter:
- Beschreibungsdatei der Datendatei und in welche Tabellen/Spalten eingelesen werden soll. (Beispiel lade_pat_auf_ctl.xml)
- eigentliche Datendatei (Beispiel pat_auf.txt)
Die Beschreibungsdatei ist im sogenannten XML-Format geschrieben. An dieser Stelle kann keine Einführung in dieses Format gegeben werden. Da die benutzten XML-Konstrukte jedoch relativ einfach sind, kann man sich ohne weiteres an Beispieldateien orientieren. Folgendes Beispiel geht von einer Datendatei aus, in dem die Felder durch sogenannte Delimiter (Begrenzer) getrennt werden. Solche Dateien enthalten manchmal in der ersten Zeile die Feldnamen.
<tabload>
Die gesamte Datei beginnt mit <tabload> und endet mit </tabload>. Als nächstes folgt ein Abschnitt <options> ... </options>. "tabload" und "options" sind sogenannte XML-Tags. Alles Tags müssen in der beschriebenen Art und Weise geöffnet und geschlossen werden. Sie dürfen sich dabei nicht überlappen, das heißt wenn ein Tag wie "options" innerhalb von "tabload" beginnt, muß es auch innerhalb von "tabload" enden. Der sogenannte XML-Prolog "<?xml version="1.0" encoding="iso-8859-1"?>" ist nur erforderlich, wenn z.B. irgendwo Umlaute benötigt werden.
<options>
<skip>1</skip>
<debug>1</debug>
<delimiter>;</delimiter>
<enclosure>"</enclosure/>
</options>
Mit "delimiter" wird angegeben, mit welchem Zeichen die Felder getrennt werden. "enclosure" gibt das Einschlußzeichen für Felder an. Häufig werden nämlich Zeichenketten-Felder wie Namen durch Zeichen wie '"' eingeschlossen, damit in diesen Zeichenketten auch Feldtrenner benutzt werden können. Mit "skip" wurde angegeben, daß die erste Zeile der Datendatei übersprungen werden soll (weil sie die Feldnamen enthält). "debug" führt zu einer umfangreichen Log-Datei, die in Zusammenhang mit einer Fehlerdatei zu einer Fehleranalyse benutzt werden kann.
Es folgt dann eine Reihe von Tabellenbeschreibungen (eingeschlossen in "table"), die ihrerseits wiederum Spaltenbescheibungen ("column") enthalten.
<table>
<name>externer_patient</name>
Als Name wird der Name der Zieltabelle, in die die Daten eingelesen werden sollen, angegeben (Groß-/Kleinschreibung ist hier egal). Aus einem Quelldatensatz können durchaus mehrere Tabellen gefüllt werden, wie hier "externer_patient" und "abteilung_patient_beziehung".
<column>
<name>PATIENTEN_ID</name>
<index>1</index>
<primary_key>1</primary_key>
</column>
Als Name wird der Name der Zielspalte, in die die Daten eingelesen werden sollen, angegeben (Groß-/Kleinschreibung ist hier egal). Mit "index" wird angegeben, aus dem wievielten Feld der Zeile die Daten gelesen werden sollen. Ein Feld kann mehrmals gelesen werden (z.B. wird das erste Feld in diesem Beispiel sowohl für PATIENTEN_ID in EXTERNER_PATIENT als auch für FK_EXTERNE_PATIENTEN_ID in ABTEILUNG_PATIENT_BEZIEHUNG benutzt. Gleichzeitig wird angegeben, daß der Inhalt dieses Feldes als Teil des Primärschlüssels benutzt werden soll. Hierüber wird gewährleistet, daß, wenn im gleichen oder in einem Folgeexport ein Patient mit gleichem Primärschlüssel auftaucht, ein Update auf EXTERNER_PATIENT erfolgt statt eines Inserts.
<column>
<name>IMPORT_QUELLE</name>
<fixed_value>daten_historisch</fixed_value>
<primary_key>1</primary_key>
</column>
Als Quelle eines Feldes können auch feste Werte angegeben werden. Angenommen, es sollen Altdaten übernommen werden, so wird das Feld IMPORT_QUELLE mit "daten_historisch" gefüllt.
<column>
<name>NAME</name>
<index>2</index>
</column>
...
<column>
<name>GESCHLECHT</name>
<index>4</index>
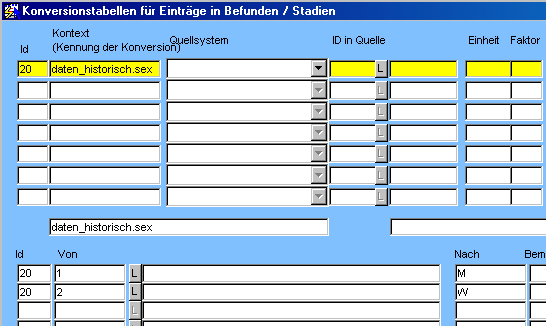
<conversion_context>daten_historisch.sex</conversion_context>
</column>
Da das Geschlecht anders als im GTDS codiert ist, muß es konvertiert werden.
<column>
<name>GEBURTSDATUM</name>
<index>5</index>
<format_mask>dd.mm.yyyy</format_mask>
</column>
Datumsangaben müssen in der Regel mit einer Format-Maske angegeben werden.
...
<column>
<name>AENDERUNGSDATUM</name>
<system_value>sysdate</system_value>
</column>
Statt fester Werte können Felder auch mit Systemwerten wie dem aktuellen Zeitpunkt (sysdate) oder dem Datenbank-Benutzer (user) gefüllt werden.
</table>
<table>
Hier beginnt die Beschreibung der nächsten Tabelle
<name>abteilung_patient_beziehung</name>
<column>
<name>FK_EXTERNE_PATIENTEN_ID</name>
<index>1</index>
<primary_key>1</primary_key>
</column>
<column>
<name>FALL_NUMMER</name>
<index>9</index>
<primary_key>1</primary_key>
</column>
<column>
<name>IMPORT_QUELLE</name>
<fixed_value>daten_historisch</fixed_value>
<primary_key>1</primary_key>
</column>
<column>
<name>FK_ABTEILUNGABTEIL</name>
<index>10</index>
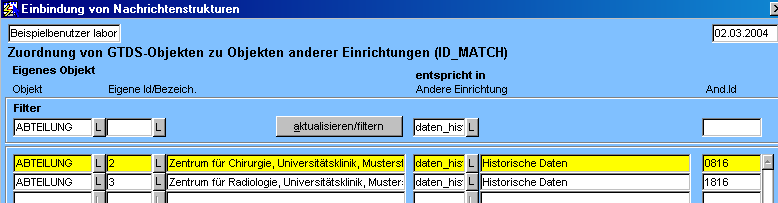
<id_match_source>daten_historisch</id_match_source>
<id_match_context>ABTEILUNG</id_match_context>
</column>
Das Ladeprogramm bietet auch die Möglichkeit, auch auf Konversionsdefinitionen aus der Tabelle ID_MATCH zurückzugreifen.
...
</table>
</tabload>
Nachfolgend wird die komplette Document Type Definition (DTD) für die Beschreibung einer Konfigurationsdatei dargestellt.
<!ELEMENT tabload (options?, pre_import*, post_import*, table+)>
Eine Konfigurationsdatei besteht aus (optionalen=?) Optionen und mindestens einer (+) Tabellenbeschreibung.
<!ELEMENT options (
delimiter|
enclosure|
skip|
debug|
field_names|
decimal_character|
group_separator|
allow_truncation|
record_xpath|
trimming|
jdbc_datasource|
source_user|
source_pwd|
source_sql|
source_type_mappings
)*>
Innerhalb von "options" können die genannten Optionen angegeben werden.
Sie wurden größtenteils schon im Beispiel beschrieben.
"decimal_character" und "group_separator" werden für die Bearbeitung von Gleitkommazahlen benötigt (kaum im GTDS vorhanden).
"jdbc_datasource" gibt den JDBC-Connect-String an, source_user/pwd die Login-Daten und source_sql das SQL-Statement, mit dem aus einer anderen Datenbank (einschließlich ODBC) Daten gelesen werden können.
"record_xpath" gibt an, wie die "Sätze" innerhalb einer XML-Quelldatei verarbeitet werden.
<!ELEMENT table (name, set_user_insert?, set_user_insert?, set_sysdate_insert?, set_sysdate_update?, no_action_on_missing_key?, mode?, trimming?, column+)>
<!ELEMENT column (
name,
(
index|
(position_start,position_end)|
named_index|
fixed_value|
system_value|
(source_table,source_column)|
column_xpath|
non_base_table
),
(
format_mask|
conversion_context|
(id_match_source, id_match_context)|
decimal_character|
group_separator|
primary_key|
simple_function|
calculate_function|
hexStringToString|
trimming|
read_url
)*
)>
Für eine Tabelle kann mit "mode" (insert, update oder update_or_insert) angegeben werden, ob nur die entsprechende Funktion aufgerufen wird.
Mit den set....-Elementen wird angegeben, welche Felder bei insert oder update mit der Variablen user bzw. sysdate gefüllt werden.
no_action_on_missing_key mit Inhalt "1" ermöglicht, daß der Import fortgesetzt wird, wenn eine Primärschlüsselinformation fehlt (siehe primary_key).
Für eine Spalte muß der Namen und die Quelle der Daten angegeben werden. Quelle kann sein:
- index: Angabe des wievielten Feldes der Eingabezeile (für "delimited"-Dateien)
- named_index: Angabe des Spaltennames eines Eingabedatensatzes (für JDBC-Datenquellen oder Delimited-Dateien mit Spaltenüberschriften)
- position_start/end: Angabe der Position des ersten und letzten Zeichens innerhalb der Zeile (für Dateien mit festen Feldpositionen)
- parameter: über Kommandozeile übergebener Parameter (<parameter>=<wert>)
- fixed_value: eine feste Zeichenkette
- system_value: eine Systemwert (sysdate oder user, siehe Beispiel)
Dieser Angabe können weitere Optionen folgen
- format_mask: Angabe für die Interpretation von Datumswerten. Wenn z.B. Datumswerte in der Form 21.03.2004 geladen werden, so lautet die Formatmaske dd.mm.yyyy .
- conversion_context: Der Wert in der Datendatei soll gemäß den Definitionen in Konversionstabellen unter dem angegebenen Kontext konvertiert werden (könnte z.B. für Umwandlung von Geschlecht in 1/2 nach GTDS-Geschlecht M/W benutzt werden).
- id_match_source/context: Der Wert in der Datendatei soll gemäß den Definitionen in ID_MATCH konvertiert werden, wobei "source" der anderen Einrichtung entspricht und "context" dem Objekt (z.B. ABTEILUNG) (könnte z.B. für Umwandlung von Abteilung_ID in einer Quelle nach GTDS-Abteilung benutzt werden).
- Die übrigen Parameter wurden bereits beschrieben.
Trimming erlaubt auf allen Ebenen zu definieren, ob Inhalte getrimmt werden sollen. Zulässig sind "N" (Nein), "B" (beide Seiten, links und rechts), "L" (links) und "R" (rechts).
Für feste Feldpositionen ist "B" (beide Seiten) voreingestellt.
Mit "pre_import" und "post_import" können SQL-Anweisungen vor bzw. nach dem Import ausgeführt werden, die eine Vorbereitung oder Nachbearbeitung der Daten ermöglichen.
<!ELEMENT pre_import (sql, bind_param*)>
<!ELEMENT post_import (sql, bind_param*)>
<!ELEMENT bind_param (name, source, field)>
"sql" enthält die SQL-Anweisung; mit "bind_param" werden Parameter an die SQL-Anweisung übergeben. Dabei ist bei ORACLE der Name des Parameters egal, als source ist derzeit nur "PARAMETER" möglich wobei "field" den Namen des übergebenen Parameters bezeichnet.
<ELEMENT delimiter (#PCDATA)>
<ELEMENT enclosure (#PCDATA)>
<ELEMENT skip (#PCDATA)>
<ELEMENT debug (#PCDATA)>
<ELEMENT name (#PCDATA)>
<ELEMENT index (#PCDATA)>
<ELEMENT position_start (#PCDATA)>
<ELEMENT position_end (#PCDATA)>
<ELEMENT format_mask (#PCDATA)>
<ELEMENT fixed_value (#PCDATA)>
<ELEMENT system_value (#PCDATA)>
<ELEMENT conversion_context (#PCDATA)>
<ELEMENT id_match_source (#PCDATA)>
<ELEMENT id_match_context (#PCDATA)>
<ELEMENT primary_key (#PCDATA)>
<ELEMENT group_separator (#PCDATA)>
<ELEMENT decimal_character (#PCDATA)>
<ELEMENT sql (#PCDATA)>
<ELEMENT source (#PCDATA)>
<ELEMENT field (#PCDATA)>
<ELEMENT simple_function (#PCDATA)>
<ELEMENT calculate_function (#PCDATA)>
<ELEMENT bind_column (#PCDATA)>
<ELEMENT non_base_table (#PCDATA)>
<ELEMENT source_table (#PCDATA)>
<ELEMENT source_column (#PCDATA)>
<ELEMENT jdbc_datasource (#PCDATA)>
<ELEMENT source_user (#PCDATA)>
<ELEMENT source_pwd (#PCDATA)>
<ELEMENT source_sql (#PCDATA)>
<ELEMENT record_xpath (#PCDATA)>
<ELEMENT allow_truncation (#PCDATA)>
<ELEMENT column_xpath (#PCDATA)>
<ELEMENT hexStringToString (#PCDATA)>
<ELEMENT character_conversion (#PCDATA)>
<ELEMENT trimming (#PCDATA)>
<ELEMENT read_url (#PCDATA)>
<ELEMENT mode (#PCDATA)>
<ELEMENT set_sysdate_insert (#PCDATA)>
<ELEMENT set_sysdate_update (#PCDATA)>
<ELEMENT set_user_insert (#PCDATA)>
<ELEMENT set_user_update (#PCDATA)>
<ELEMENT field_names (#PCDATA)>
<ELEMENT named_index (#PCDATA)>
Innerhalb von DTDs kann nicht näher bestimmt werden, wie der Text-Inhalt eines Tags (#PCDATA) aussehen darf. Ungültige Inhalte (z.B. negative Positionen oder ungültige Zahlenangaben) führen ggf. zu Fehlfunktionen oder Programmabbrüchen.
Beispiel-Import
Es soll die Datei pat_auf.txt mittels der Beschreibung lade_pat_auf_ctl.xml geladen werden.
Die Daten werden unter der Quelle "daten_historisch" geladen. Daher wird zunächst eine entsprechende Einrichtung im GTDS angelegt.
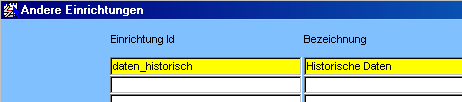
Für das Laden der Daten muß an zwei Stellen konvertiert werden, einmal über die Konversionstabellen (Geschlecht) und einmal über ID_Match (Abteilung).
Damit sind die Vorbereitungen für den Import abgeschlossen. Für den Aufruf des Import-Programms kann die Batch-Datei "tabload.bat" benutzt werden. Dazu wird die Eingabeaufforderung geöffnet und in das GTDS-Verzeichnis gewechselt.
C:\GTDS>setjavadb.bat
JAVADB_USRPASS ist beispiel/beispiel@jdbc:oracle:thin:@127.0.0.1:1521:gtds
WEBGTDS_PFAD ist c:\WEBGTDS
C:\GTDS>tabload.bat hilfe\lade_pat_auf_ctl.xml hilfe\pat_auf.txt
Die Batch-Datei tabload.bat benötigt die Umgebungsvariablen JAVADB_USRPASS und WEBGTDS_PFAD. In "geschützten" Umgebungen kann es vertretbar sein, die Datei "setjavadb.bat" so anzupassen, daß man diese beiden Parameter über "setjavadb.bat" setzt (Achtung Paßwort im Klartext!). Alternativ können nur die entsprechenden Parameter-"Bestandteile" gtds_user und gtds_pwd über "SET" manuell gesetzt werden und der Rest über "setjavadb.bat" ergänzt werden.
Die Datendatei und die Beschreibungsdatei müssen sich natürlich nicht im GTDS-Verzeichnis befinden. Im Verzeichnis der Datendatei entstehen Logdateien, in denen Ausgaben und Fehler protokolliert werden. Nach dem Laden der o.g. Ladedatei sind unter "Krankenhauspatienten folgende Daten zu finden:
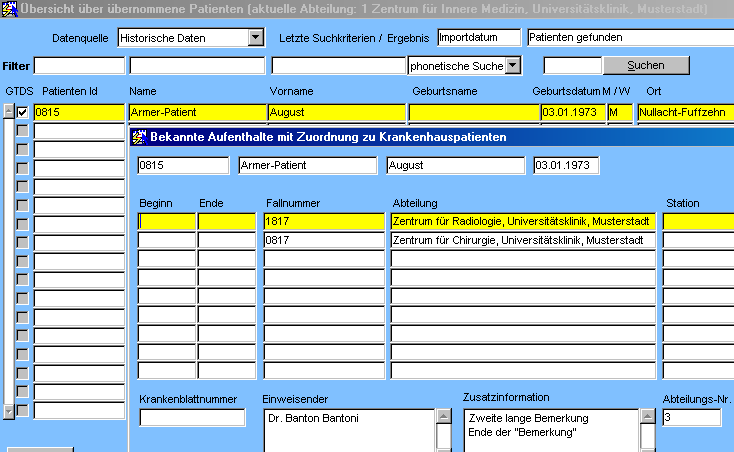
Das Laden von Tabellen kann auch aus einer Maske heraus gesteuert werden, die dann an geeigneter Stelle (z.B. in der Maske Krankenhauspatienten) aufgerufen wird.
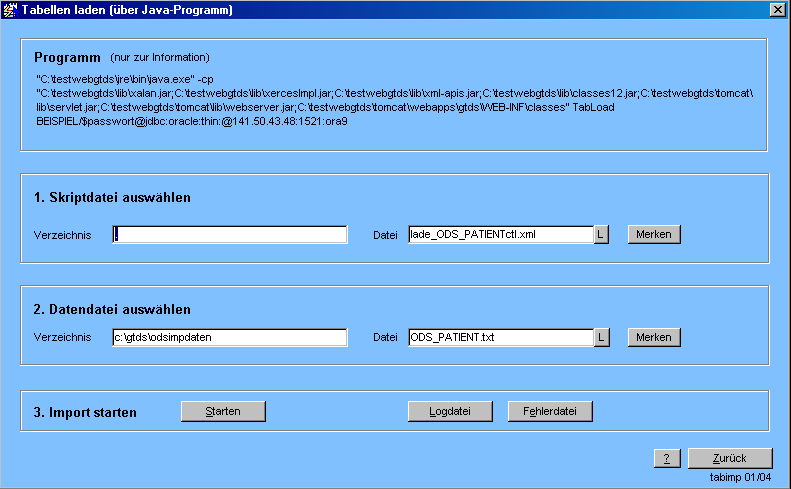
Hinweise:
- Vorlagen für Beschreibungs-Dateien können über das SQL-Skript "genimpctl.sql" generiert werden (z.B. @genimpctl EXTERNER_PATIENT).
- Bei Fehlern wird die Verarbeitung abgebrochen.
- Für Dateien im "delimited" Format gilt: Es muß darauf geachtet, daß Einschlußzeichen sauber "geschachtelt" sind, da ein Feld, das mit einem Einschlußzeichen beginnt bis zum nächsten Einschlußzeichen gelesen wird. Dabei werden auch Trennzeichen und Zeilenenden "ignoriert" und es wird gegebenenfalls über mehrere Zeilen hinweggelesen, was ja durchaus gewünscht sein kann, um längere Texte zu verarbeiten. Um Einschlußzeichen innerhalb eines Feldinhalts darzustellen, müssen diese verdoppelt werden (also z.B. "" für ein ").
- Fehler treten auf, wenn zuwenig Felder gelesen werden, als der Feldindex es erfordert oder bei wenn bei Dateien mit festen Feldpositionen die Zeilenlänge zu kurz ist. Überschreitungen der Zeilenlängen führen nicht zu Fehlern. Ebensowenig wird geprüft, ob eine Datei im "delimited" Format in jeder Zeile gleich viele Felder enthält.
Weitere Beispiele Laden von Nachsorgedaten Datendatei