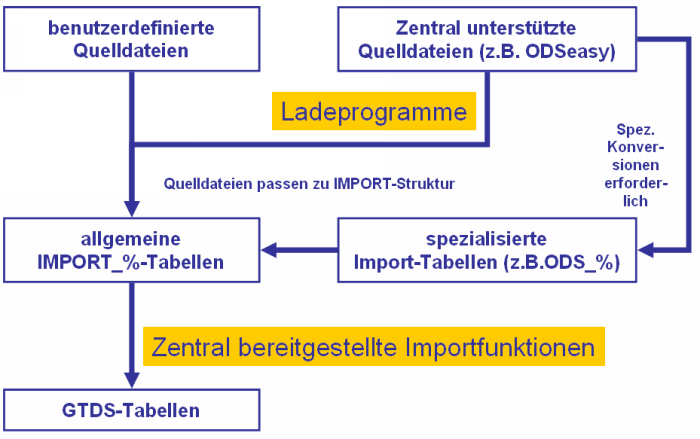
Ziel der allgemeinen Importschnittstelle ist es, erfahrenen Anwendern ein Werkzeug an die Hand zu geben, mit dem sie Daten aus anderen Systemen einlesen können. Solche Anforderungen können sich ergeben, wenn Daten aus anderen, insbesondere Nicht-GTDS-Registern, historischen Datensammlungen oder aus wissenschaftlichen Arbeiten importiert werden sollen.
Dabei ist das Verarbeiten solcher Daten ein relativ komplexer Vorgang, mit dem eine Reihe von Prüfungen verbunden ist, da u.a. folgende Probleme auftreten können:
Daher werden alle Daten zunächst in Zwischentabellen, sogenannte "IMPORT_"-Tabellen geladen. Diese Import Tabellen sind auf die GTDS-Struktur abgestimmt. Diese Tabellen ergänzen die bereits existierenden "EXTERNE_"-Tabellen, die ursprünglich vor allem für die Übernahme von Daten z.B. aus dem Krankenhausinformationssystem gedacht waren.
Die Daten in die Zwischentabellen einzulesen liegt grundsätzlich zunächst in der Hand der Anwender, wobei für verbreitete Anwendungsfälle auch zentral Hilfsmittel bereitgestellt werden (z.B. ODSeasy). Die Zwischentabellen werden nachfolgend näher beschrieben. Programme, die Daten in die Zwischentabellen einlesen, sind dafür verantwortlich, diese entsprechend den Beschreibungen einzulesen. Ein Hilfsmittel für das Einlesen von z.B. ASCII-Dateien mit festen Feldpositionen oder Feldtrennern wird zentral bereitgestellt. Dieses Programm ist auch in der Lage, bestimmte Konversionen zu unterstützen
Die folgenden Tabellen sind Bestandteil der Import-Tabellen
Folgende Tabellen werden darüber hinaus im Rahmen des Imports aus Krankenhaussystemen benutzt (z.B. HL7)
Über die "datentragenden" Import-Tabellen hinaus sind eine Reihe von Konfigurationstabellen erforderlich, um die im Rahmen eines Imports notwendigen Umsetzungen von Inhalten vorzunehmen.
Die Import-Tabellen stehen folgendermaßen untereinander in Beziehung (nicht dargestellt sind IMPORT_ABSCHLUSS und IMPORT_TODESURSACHE (Bezug zum Patienten), IMPORT_KLASSIFIKATION (Handhabung wie IMPORT_TNM) sowie IMPORT_NEBENWIRKUNG (Bezug entweder zu Bestrahlung/Teilbestrahlung oder zu systemischer Therapie / Zyklus)
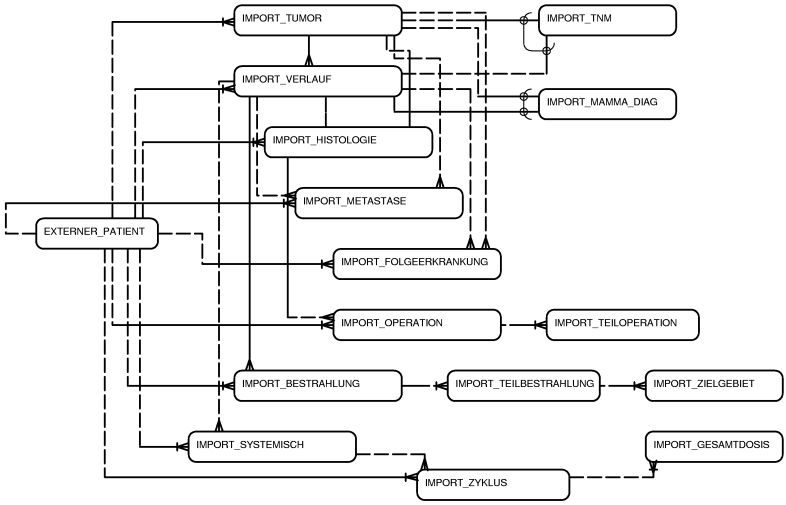
Allen Tabellen gemeinsam sind die Felder "IMPORT_QUELLE" und "PATIENTEN_ID", die kennzeichnen, zu welchem Patienten in welcher Quelle der jeweilige Datensatz gehört. Darüber hinaus haben die am externen Patienten direkt "hängenden" eine eigene ID (EXTERNE_TUMOR_ID, EXTERNE_VERLAUF_ID, ...), die in Kombination mit der Quelle und der Patienten-ID den eindeutigen Schlüssel eines Datensatzes bildet. Diese Kombination wird in der Tabelle "SONSTIGE_FREMD_ID" gespeichert, sobald ein entsprechender Datensatz importiert oder einem bereits im GTDS gespeicherten Datensatz zgeordnet wurde. Die weiteren Tabellen sind nur indirekt vom Patienten abhängig. Hier wird davon ausgegangen, daß diese nicht einzeln sondern nur komplett mit dem übergeordneten Datensatz importiert werden.
Über die genannten hierarchischen Beziehungen der Tabellen untereinander hinaus gibt es eine Reihe von Quervernetzungen, die sinngemäß die Situation im GTDS wiedergeben: Therapien sind Verläufen und (nicht eingezeichnet) Tumoren zugeordnet (über die EXTERNE_VERLAUF_ID), Verläufe, Metastasen, Folgeerkrankungen (optional) und Histologien Tumoren. Bei TNM und Mamma_Diag kann entweder eine Zuordnung zu einem Tumor oder zu einem Verlauf bestehen. Ist die EXTERNE_VERLAUF_ID leer, so bedeutet das für die vorgenannten Tabellen (außer Therapie), daß bei der Übernahme die Zuordnung im GTDS zu den Diagnosedaten erfolgt.
Diese wird in der Regel beim Einleseprozeß gesetzt. Ein Hersteller eines Systems kann hier aber auch eine eindeutige Kennung der Instanz einsetzen, so dass diese beim Einlesen mit berücksichtigt werden kann.
Diese muss, da beim Einlesen Teil des Primärschlüssels, über mehrere Exportläufe konstant bleiben.
Die über mehrere Exportläufe konstante Identifikation eines Patienten.
EXTERNE_xxxxx_IDs ermöglichen, zumindest im Kontext mit Import_Quelle und Patienten_ID, eine eindeutige Identifikation des einzulesenden Satzes, insbesondere wenn sie in der entsprechenden Beschreibung als Primärschlüssel gekennzeichnet sind. D.h. aus dieser Kombination entscheidet das Import-Programm, ob es ein Insert oder Update des Import-Datensatzes durchführt.
Externe_IDs ohne Primärschlüsselkennzeichnung sind einfache Fremd-Verweise (wiederum jeweils in Kombination mit Import_Quelle und Patienten_ID, häufig externe_Tumor_ID und Externe_Verlauf_ID).
Sonderfall TNM: Ein IMPORT_TNM-Datensatz muß entweder dem Tumor (Externe_Tumor_ID) oder einem Verlauf (Externe_Verlauf_ID) zugeordnet sein. Das ist dann jeweils in Kombination mit Import_Quelle und Patienten_ID eine gültige Primärschlüsselkombination. Alternativ kann für den Primärschlüssel auch die Externe_TNM_ID genutzt werden. Dies entbindet aber nicht von der Notwendigkeit der Zuordnung zu einem Tumor und/oder einem Verlauf.
Dies Externen IDs müüsen, da sie beim Einlesen Teil des Primärschlüssels oder von Fremdschlüsseln sind, über mehrere Exportläufe konstant bleiben.
In der Beschreibung der GTDS-Tabellen und der obigen Grafik sind die jeweiligen Beziehungen hinterlegt.
Diese Felder ermöglichen den Transfer und die Unterscheidung von Organisationseinheiten im sendenden System. SUBQUELLE_ID kann je nach Einstellung beim Export ins GTDS in den Datensatzeigner oder die durchführende Abteilung / den durchführenden Arzt übertragen werden. Hierzu werden die IDs über ID_Match aufeinander abgebildet. SUBQUELLE_TEXT entspricht dem jeweiligen "DUCHGEFUEHRT_VON"-Text der Zieltabelle.
Das Import_Datum wird bei INSERT und UPDATE, das ERSTIMPORT_DATUM nur bei INSERT durch den Einleseprozeß gesetzt (Ausnahme Externer_Patient: AENDERUNGSDATUM bei INSERT und UPDATE, IMPORT_DATUM nur bei INSERT). Diese Information wird genutzt um zu filtern, welche Information im aktuellen Einleseprozeß enthalten waren.
Datum/Zeitstempel, den die Ursprungsdaten im sendenden System haben. Diese Information kann zum Vergleich der Aktualität von GTDS und importierten Daten verwendet werden.
Wird durch die Verarbeitung im GTDS gefüllt.
Sondernutzung bei Import von Daten aus Tumorkonferenzmodul des GTDS
Grundsätzlich ist ein Import von Datensätzen im CSV oder mit festen Feldpositionen mit Dateien gemäß der Struktur der Import-Tabellen möglich. Am leichtesten geht die Entwicklung bei der Verwendung von Spaltenüberschriften in der ersten Zeile. Aber es sind auch XML-Formate und ein JDBC oder ODBC-Zugriff einrichtbar.
Häufig liegt im Quellsystem eine einfachere Datenstruktur vor. So könnten in einer "Zeile" einer Quelldatei durchaus Felder aus EXTERNER_PATIENT, IMPORT_TUMOR, IMPORT_HISTOLOGIE und IMPORT_TNM untergebracht sein.
Das Einleseprogramm ordnet dann beim Import die Spalten-Inhalte den einzelnen Tabellen zu und bildet ggf. künstliche Externe-IDs. Dabei muß aber z.B. in dem genannten Beispiel gewährleistet sein, dass ein Patient mit mehreren Tumoren auch als der selbe Patient erkennbar bleibt, z.B. über eine Spalte Patienten_ID. Die Tumor-Datensätze müssen dann über eine Externe_Tumor_ID unterscheidbar sein. Diese Spalten müssen nicht genau so heißen, müssen aber die entsprechende Information beinhalten. Das Einleseprogramm wird dann der IMPORT_HISTOLOGIE und dem IMPORT_TNM eine Externe_Histo_ID, bzw Externe_TNM_ID zuweisen, die faktisch der Externen_Tumor_ID entsprechen und so den Primärschlüssel für das Einlesen gewährleisten. Es wird weiterhin jeweils die Externe_Tumor_ID der jeweiligen Import-Tabelle füllen.
Einleseprogramme müssen für jede Art von Transfer neu geschrieben werden. GTDS stellt hierfür das Programm tabload zur Verfügung. Im Prinzip arbeitet dieses Programm nach in einer proprietären XML-Syntax geschriebene Mapping-Anweisungen von Inhalten in den Quellen auf die Import-Tabellen. Darüber hinaus ist es in der Lage, über SQL komplexe Nachbearbeitungsschritte durchzuführen.
Eine generelle Aussage, welche Felder Pflicht sind läßt sich nicht machen. In jedem Fall sind die Primärschlüssel bildende Felder Pflicht. Darüber hinaus kann die Optionalität lediglich aus dem betreffenden Kontext der Übertragung abgeleitet werden. So könnte theoretisch schon der Import allein einer ICD mit einem Diagnosedatum einen Wert haben, wenn diese Daten nachbearbeitet werden können. Für einen Patienten mögen Nachname, Vorname und Geburtsdatum genügen, wenn in einem anderen Prozeßschritt die Adresse komplettiert werden kann.
Mit der Maske "import" wird ein Import aus den bereits per Ladeprogramm gefüllten Tabellen vorgenommen.
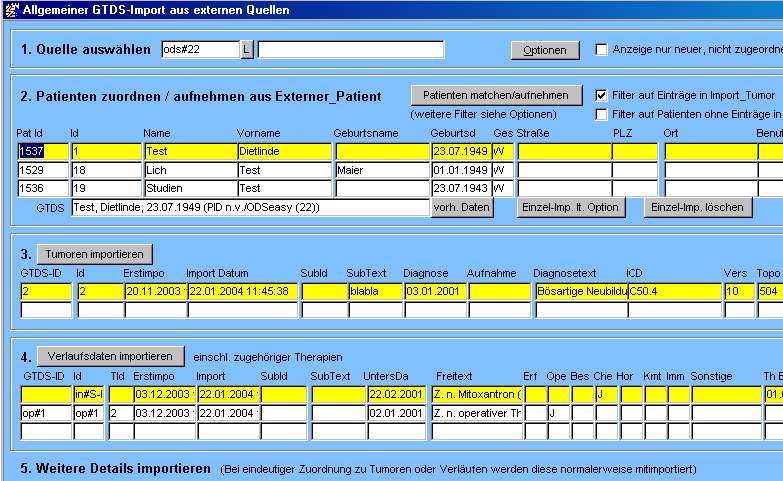
Nach ggf. Wahl der Quelle (sofern noch nicht vorbelegt), unter der die Importsätze eingeordnet sind, muß zunächst ein Abgleich der Patienten erfolgen. Dazu wird die Patienten-Match Maske aufgerufen, in der auch nicht im GTDS existierende Patienten neu aufgenommen werden können.
Als nächstes erfolgt der Import der eigentlichen Tumordaten. Dabei gibt es folgende Optionen:
Solange man mit dem Import der Daten aus einer bestimmten Quelle noch nicht vertraut ist und insbesondere auch nachdem sich eine Schnittstellenbeschreibung geändert hat, sollte man in jedem Fall zunächst testweise einige Datensätze der unterschiedlichen Art (IMPORT_TUMOR, IMPORT_VERLAUF, ...) importieren (s.u.), um zu sehen, welche Felder wie gefüllt werden und ob die Füllung korrekt erfolgt.
Erst wenn hierbei alles erwartungsgemäß läuft, kann man als nächsten "Test"-Schritt die gesamten Daten einzelner Patienten insgesamt importieren. Dabei müssen bereits Optionen angegeben werden (z.B. welche Datenarten), so daß der Knopf "Einzel-Imp. lt. Option" heißt. Dabei verhält sich der Import relativ konversativ, so daß unter Umständen bestimmte Datensätze nicht importiert werden, da nur sichere Konstellationen verarbeitet werden. Sichere Konstellationen sind:
Den kompletten Import aller Datensätze sollte man erst starten, wenn die beiden genannten Schritte erfolgreich abgeschlossen wurden und man mit den Ergebnissen vertraut ist. Im Prinzip werden hierbei Patient für Patient Einzelimporte durchgeführt. Die Maske bietet Filterfunktionen, um Patienten anzuzeigen, für die nicht verarbeitete Datensätze vorliegen, so daß Datensätze, die wegen unklarer Konstellationen nicht bearbeitet wurden, manuell nachgearbeitet werden können.
Für den Import einzelner Datensätze werden die Schritte in der auf der Maske angegeben Reihenfolge abgearbeitet. Da sich GTDS die Datensatz-Bezüge aus dem Quellsystem merkt, sollten zunächst die Tumoren und dann die Verläufe verarbeitet werden. Diesen Datensätzen zugeordnete Details wie TNM, Histo, Metastasen und Therapien werden automatisch mitimportiert. Ob ein Datensatz schon importiert (oder zugeordnet) wurde, ist jeweils am gefüllten Feld "GTDS-ID" zu erkennen. Die Importe sind alle gleich gestaltet:
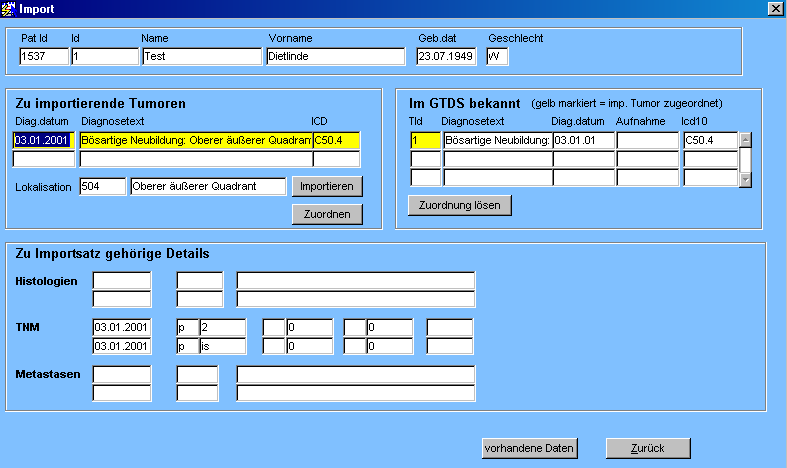
Der Nutzer sieht auf der linken Seite die Datensätze aus dem Import, auf der rechten Seite die im GTDS-bekannten Informationen. Falls im GTDS existierende Datensätze schon einem Import-Satz entsprechen, ist das jeweilig ID-Feld gelb markiert. Der Benutzer hat nun drei Möglichkeiten
Über "Optionen" gelangt man zu diversen Parametrisierungsmöglichkeiten und zur Verarbeitung ganzer Importe
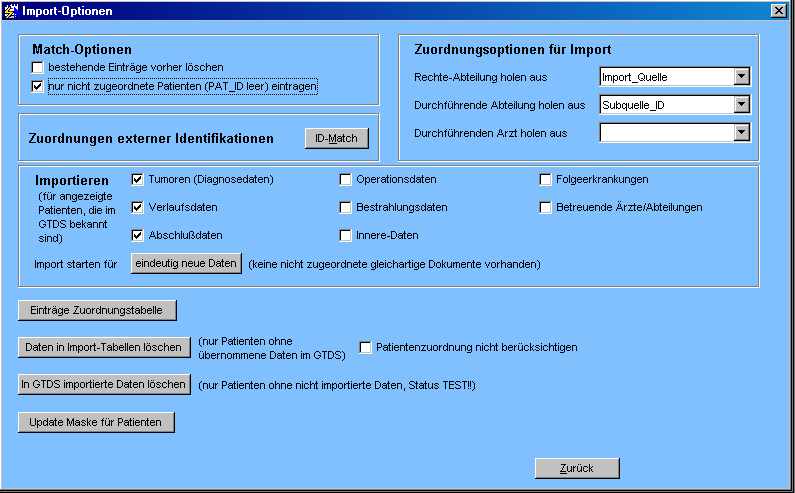
Zunächst kann festgelegt werden, wie die abteilungs-/ärztemäßige Zuordnung der zu importierenden Datensätze erfolgen soll. Ohne Angabe von Optionen wird lediglich die Rechte-Abteilung gesetzt und zwar aus dem jeweiligen Feld "Subquelle_ID" und, wenn das leer ist, aus "Import_Quelle". Andernfalls gilt das im folgenden beschriebene.
Damit Zuordnungen aus diesen IDs (Subquelle_ID/Import_Quelle) zu einer GTDS-Abteilung (oder auch Arzt) erfolgen kann, müssen entsprechende Einträge in der ID_MATCH-Tabelle vorhanden sein. Folgende Möglichkeiten stehen zur Verfügung:
Dabei kann jeweils gewählt werden, ob die Information aus der Import_Quelle oder der Subquelle_ID geholt werden soll. Ist bei Option "Subquelle_ID" das Feld "Subquelle_ID" nicht gefüllt, erfolgt kein Eintrag (Import_Quelle ist zwangsläufig immer gefüllt).
Die nächste Optionengruppe dient der Steuerung von Importen mehrerer Datensätze. Zunächst muß festgelegt werden, welche Datensätze prinzipiell importiert werden sollen. Diese Einstellung wirkt sich auf Importe der Daten einzelner Patienten und gesamter Importe aus.
"Import starten für eindeutig neue Daten" verarbeitet einen gesamten Import in der oben beschriebenen Weise.
"Einträge Zuordnungstabelle" gibt Informationen über importierte (und zugeordnete) Datensätze aus.
Sollte es notwendig werden, Import-Daten zu löschen, so müssen zunächst die in GTDS importierten Daten gelöscht werden, bevor die Daten zu einem Patienten in den Import-Tabellen gelöscht werden.
Löschvorgänge unterliegen immer einem gewissen Risiko. Wie beim Import sollte sich der Benutzer gut mit den Funktionen vertraut machen und zuächst die Funktionsweise an einzelnen Patientendaten ausprobieren. Trotz aller Vorsicht ist nicht immer auszuschließen, daß unvorhergesehene Randbedingungen oder andere Fehler zu unbeabsichtigten Ergebnissen führen. Außerdem unterliegt dieser Punkt einer gewissen Weiterentwicklung, so daß insbesondere nach Einspielen eines Updates oder Patches zur Vorsicht geraten wird.
Um die Gefahr von unbeabsichtigten Löschungen zu vermindern, prüft der Löschvorgang zunächst den Import-Status eines Patienten. Finden sich hier Hinweise auf nicht durch Import entstandene Daten, so wird nicht gelöscht, was dazu führt das teilweise importierte Daten nicht gelöscht werden können. Diese Prüfung erfaßt folgende Bereiche
Erst wenn diese Voraussetzungen vorliegen, werden alle importierten Datensätze gelöscht. Details, wie Metastasen und Folgeerkrankungen sowie zugeordnete Histologien etc., werden mit den entsprechenden Dokumenten gelöscht, ebenso Details die keine eigene Identifikation im Quellsystem haben (TNM, KLASSIFIKATION, LEISTUNGSZUSTAND, ...). Todesursachen, die per se keinen Bezug zu einem GTDS-Dokument haben, sondern nur im Kontext eines Abschlusses dargestellt werden, werden entsprechend dem Verhalten im GTDS mit dem letzten Abschluß mitgelöscht.
Die Daten in den Import-Tabellen können nur gelöscht werden, wenn für den entsprechenden Patienten keine Daten ins GTDS übernommen wurden (Einträge in SONSTIGE_FREMD_ID vorliegen) oder Verweise existieren, daß der Patient Bezüge zur Import_Quelle aufweist (PATIENTEN_ID in PATIENT, FREMD_ID in FREMD_ID, PAT_ID in EXTERNER_PATIENT). Existieren lediglich Bezüge in EXTERNER_PATIENT, so können diese mit der Option "Patientenzuordnung nicht berücksichtigen" ignoriert werden.
Beim Import nach GTDS werden in der Regel nur Datensätze eingefügt, nicht aber geändert, da mit einem Update individuell auch unterschiedliche Entscheidungen getroffen werden müßten, welche Informationen denn aktualisiert werden sollen. Insbesondere im Fall von Stammdaten und Sterbedaten kann es jedoch vorkommen, daß Aktualisierungen an einer größeren Zahl von Patienten erfolgen müssen. Für diesen Fall dient die "Update Maske für Patienten".
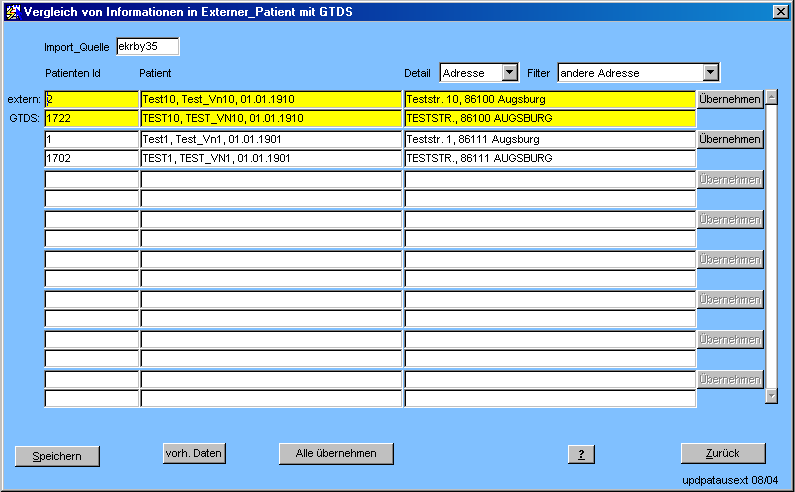
In dieser Maske können Patientendaten, die sich bezüglich bestimmter Details von denen in "EXTERNER_PATIENT" unterscheiden, ausgewählt und je nach Bedarf einzeln oder gesamt aktualisiert werden.
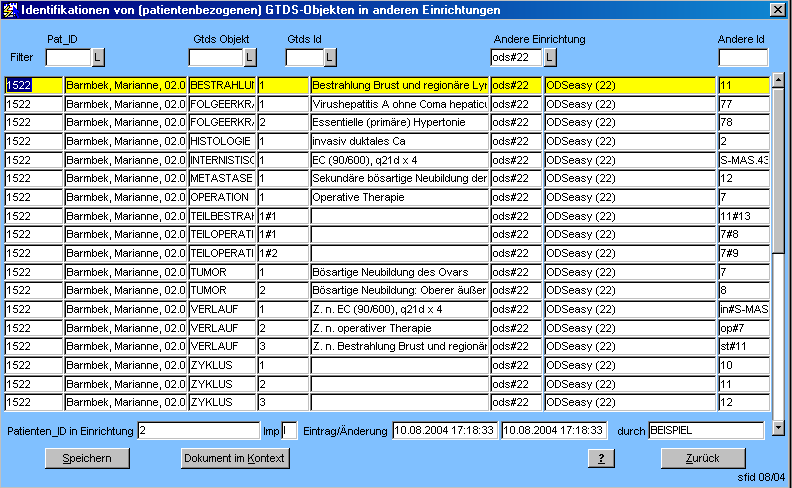
Die in SONSTIGE_FREMD_ID gespeicherten Bezüge von importierten GTDS Datensätzen zu den Import-Datensätzen sind über eine in den Dynamischen Modulen konfigurierbare Maske "Andere Identifikationen" (sfid) einsehbar. Über den GTDS-Parameter "SFID.EINGABEN_ERLAUBT" können diese Bezüge auch bearbeitbar gemacht werden (nur für Fehlersuche/-behebung).
Masken (Dateiendung fmx/fmb):