Bei der Entwicklung des GTDS wurde entschieden, daß die Anwendung auf einer möglichst redundanz- und damit widerspruchsfreien Datenbank beruhen soll. So soll zum Beispiel der Name des Patienten nicht bei jedem Tumordatensatz stehen, sondern in einer Patientenstamm-Tabelle, damit z.B. Änderungen nur an einer Stelle durchgeführt werden müssen. Des weiteren werden zum Beispiel auch Metastasen nicht in der Tumortabelle gespeichert, weil sonst z.B. nur eine begrenzte Anzahl von Metastasen gespeichert werden könnte (z.B. Metastase1 bis Metastase3). Es ist daher sinnvoller, Metastasen in einer Extra-Tabelle zu speichern. Solche Überlegungen wurden für eine Vielzahl von Informationen durchgeführt. Dieses Vorgehen, EDV-technisch "Normalisierung" genannt, führte dazu, daß die Daten innerhalb des GTDS auf eine Vielzahl von Tabellen verteilt sind.
Bei einer Auswertung möchte man andererseits häufig wissen, welcher Tumor eine Metastase verursacht hat und wie die Person heißt oder wann sie geboren ist. Zu diesem Zweck muß man Tabellen wieder zusammenführen. Die Sprache hierzu nennt sich SQL und muß relativ aufwendig erlernt werden. Darüber hinaus muß man das sogenannte Datenmodell des GTDS kennen, um die Tabellen richtig zusammenzuführen. Diese Erfahrungen können jedoch nicht an jedem Ort vorausgesetzt werden. Hier bieten sich zwei Strategien an:
Das erste Vorgehen hat den Vorteil, daß es leicht zu starten ist und wenige Angaben als Parameter benötigt. Dieser Vorteil ist aber gleichzeitig ein Nachteil, denn bei allen Bemühungen um Parametrisierung sind diese Berichte relativ starr und die Wahrscheinlichkeit ist groß, daß der nächste Benutzer eine leicht veränderte Fragestellung hat, die dann nicht mehr mit den bestehenden Berichte zu lösen ist. Solche Berichte eignen sich demnach nur für Fragestellungen, die sich kaum verändern, aber häufig, z.B. wie eine monatliche Leistungsstatistik häufig gebraucht werden. Eine Liste von solchen Berichten (entsprechend Registerbezug in der Maske Dynamisches Modul) findet sich hier.
Das zweite Vorgehen hat zunächst den Nachteil, daß nach der Zusammenführung von Daten diese auch analysiert werden müssen. Hierzu muß der Benutzer meist weitere Programme wie Tabellenkalkulations-Programme (z.B. MS-Excel) oder Statistikprogramme (wie z.B. SPSS) einsetzen. Dafür können Auswertungen sehr leicht, d.h. ohne zentrale Programmierung durchgeführt werden. Diese Tabellen werden "Auswertungstabellen" genannt.
Für beide Verfahren ist ein grundsätzliches Verständnis erforderlich. Beim ersten Verfahren sollte sich der Benutzer informieren, was ein fertiger Bericht tatsächlich zählt, um die Ergebnisse richtig interpretieren zu können. Es gibt eine Vielzahl von Berichten, angesichts derer auch die Entwickler häufig im Quelltext nachsehen müssen, um adäquat Auskunft geben zu können.
Auch für die Anwendung von Auswertungstabellen muß der Benutzer wissen, welche Idee hinter der jeweiligen Tabelle und ihren Spalten steckt, um sie korrekt anzuwenden zu können. Dies soll an folgendem Beispiel erläutert werden:
Hinter der Tabelle AUSWERTUNG steckt die Idee, daß jeder Datensatz genau einen Tumor repräsentiert. Die Tabelle enthält auch einige Detailaussagen über die Therapie. Da aber bei einem Tumor jedoch häufig mehrere Therapien, beispielsweise mehrere Operationen, durchgeführt werden, können bestimmte Details nur von der ersten Therapie, also in diesem Fall der ersten Operation einbezogen werden, auch wenn die vielleicht wichtigere Operation erst im zweiten Schritt erfolgt ist. Es wäre also falsch, sich für die Analyse, welche operative Therapie erfolgt ist, nur auf diese Information zu stützen.
Eine Auswertung besteht in der Regel aus folgenden Schritten:
Häufig werden auch Kombinationen von Bedingungen verlangt, die in der Regel über ein logisches UND (SQL: AND) verknüpft werden. Vorsicht ist geboten bei Kombinationen von logischem ODER "(SQL: OR). Zum einen müssen hier häufig Klammern gesetzt werden, um ODER und UND richtig zu verknüpfen. Zum anderen können sich unterschiedliche Grundgesamtheiten, die sich durch scheinbar ausschließende Kriterien unterscheiden, sich trotzdem überschneiden.
Beispiel: Werden für die erste Grundgesamtheit Fälle herausgesucht, deren Diagnosedatum oder deren Aufnahmedatum im Jahr 2003 liegen und für die zweite Grundgesamtheit die, deren Diagnosedatum oder deren Aufnahmedatum im Jahr 2004 liegen, dann sind diejenigen Fälle, deren Diagnosedatum im Jahr 2003 liegt, das Aufnahemdatum jedoch in 2004, in beiden Grundgesamtheiten enthalten.
Bei der Verknüpfung von Bedingungen ist es im allgemeinen ratsam, bei der späteren Darstellung anzugeben, wie sich die zunehmende Einschränkung auf die Zahlen auswirkt. Beispiel: Im Registerbestand sind derzeit 14678 Fälle. Von diesen wurden 3523 im Jahr 2003 aufgenommen. Davon sind 234 Mammakarzinome. Von diesen wurden 212 durch Abteilungen unseres Brustzentrums mitbehandelt.
Unter dem Aspekt, auch die Qualität der Daten zu kontrollieren, ist es in der Regel sinnvoll, nicht nur einen einzelnen Wert (z.B. "Stadium I") zu zählen, sondern eine Analyse aller auftretenden Werte und ihrer Häufigkeiten durchzuführen. Hierbei bekommt man einen Überblick über die Vollständigkeit der Daten: Wie häufig sind keine Werte vorhanden oder es ist ein unspezifischer Wert ("X", keine Angabe, unbekannt, ...) eingetragen? Sind unzulässige Werte eingetragen? Insbesondere wenn häufig Leerwerte oder "X"-Werte auftreten, sind Schlußfolgerungen aus den Daten nur begrenzt möglich. Zudem werden bei der Häufigkeitsanalyse aller Werte deutlich, welche Werte ggf. zusammengefaßt werden können. Angenommen, es würde nur abgefragt, ob die T-Kategorie = 1 ist. Eine Häufigkeitsanalyse würde hier aufdecken, daß einige Fälle auch "1a" oder "1b" enthalten, die dann zu "1" gezählt werden müssen.
Jeder, der an das Register mit einem Auswertungswunsch herantritt, muß also wenigstens sprachlich formulieren können, welche Datensätze (Fälle, Therapien) er analysiert haben möchte und welche Variablen von diesen Datensätzen interessieren.
Das eben gesagte soll nun an einem Beispiel nachvollzogen werden. Angenommen jemand möchte, aufgeschlüsselt nach pT, wissen, wie die operative Therapie bei Mammakarzinom bei allen von Abteilung 1 mitbehandelten und in den Jahren 2001-2003 behandelten Patienten erfolgte.
Beim Aufruf der Auswertungsmaske werden alle für den Benutzer zugreifbaren, ggf. auch nur die Patienten angezeigt, die von einer bestimmten Abteilung mitbehandelten Patienten angezeigt. Nur der Benutzer OPS$TUMSYS kann wirklich alle Fälle betrachten, alle anderen Benutzer , auch sogenannte Leitstellenbenutzer, bekommen maximal diejenigen zu sehen, die von Abteilungen mitbetreut werden, auf die sie als zugriffsberechtigt eingetragen sind. In diesem Fall muß also die gefragte Abteilung 1 für den Benutzer zugreifbar sein. Im ersten Schritt geht es darum, die Grundgesamtheit einzuschränken. Zunächst sollen alle Mammakarzinome herausgesucht werden. Der Einfachheit halber (ohne Rücksicht auf den histologischen Typ) sollen diese über die Lokalisation "50" bestimmt werden. Die Maske wird mit "F7" in den Abfragemodus versetzt und der Cursor wird in das Feld LOKALISATION gesetzt.
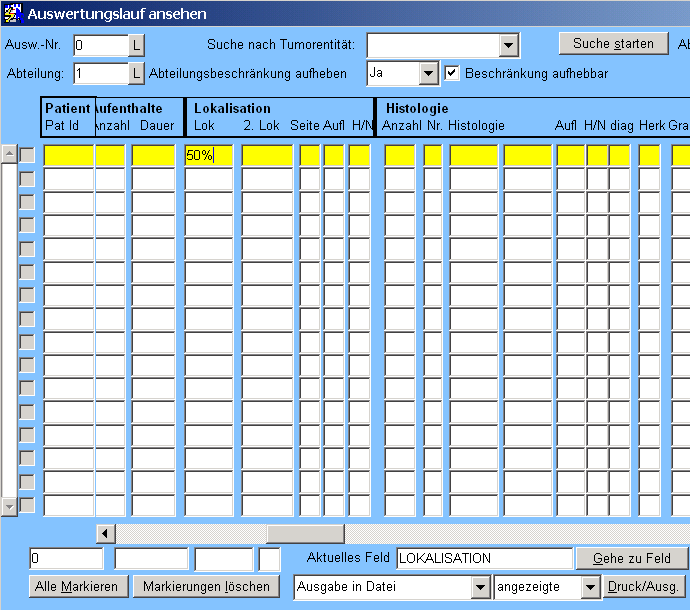
Im Abfragemodus können gewünschte Filter-Werte einfach in das betreffende Feld gesetzt werden. "50%" heißt, daß nach der 50 beliebig viele Zeichen folgen dürfen. In diesem Fall werden also sämtliche Lokalisationscodes der Mamma erfaßt. Mit "F8" wird die Abfrage ausgeführt:
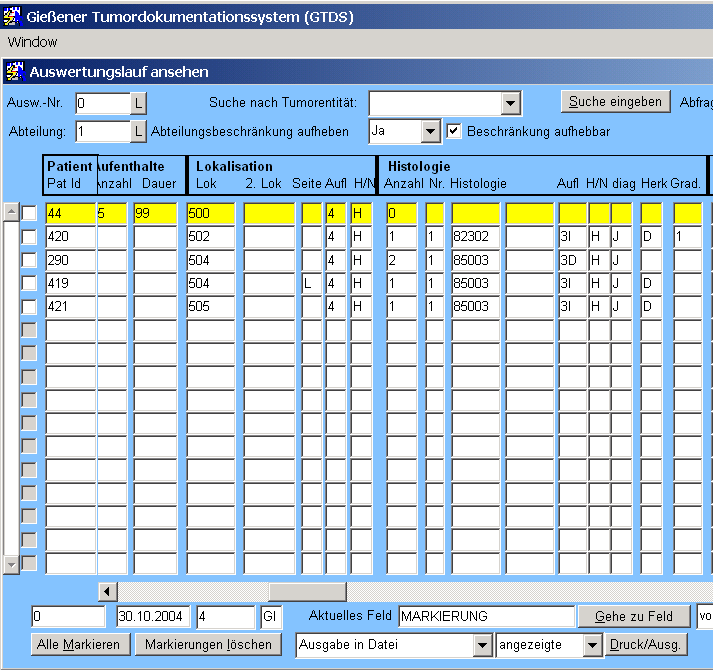
Das Ergebnis ist an diesen Testdaten sehr übersichtlich. Drückt man statt "F8" die Tastenkombination "Umschalt-F2", bekommt man die Zahl der gefundenen Datensätze in der Statuszeile angezeigt. Für die weitere Einschränkunkung der Grundgesamtheit soll die Abfrage-Hilfsfunktion benutzt werden. Nach "Speichern" der Abfrage gelangt man in das entsprechende Fenster:
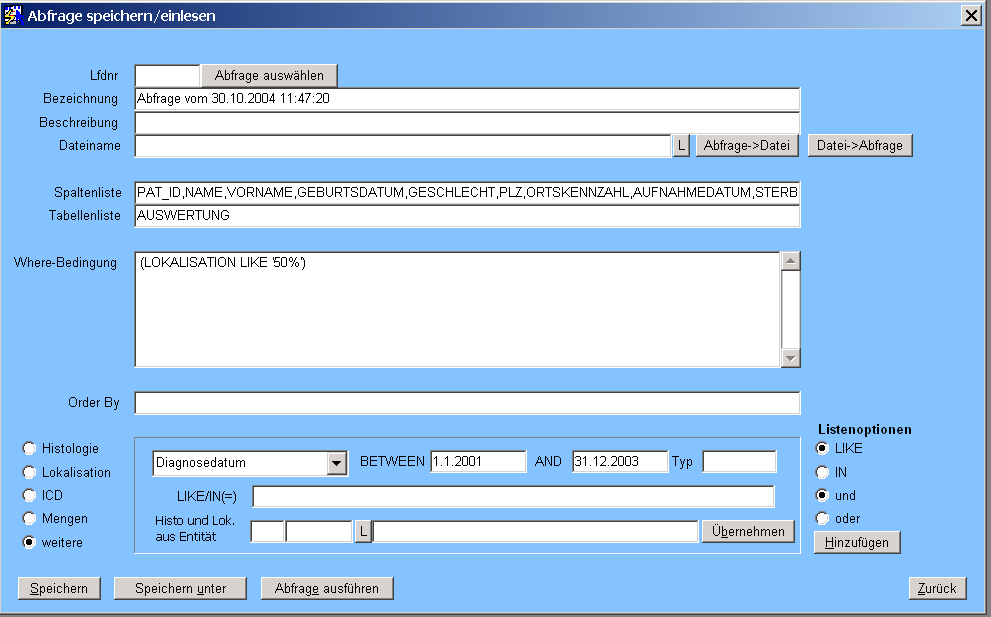
Wie man sieht, ist das Filtern nach Lokalisation bereits in die WHERE-Bedingung übernommen worden. Im unteren Teil der Masker ist in "weitere" bereits das Diagnosedatum ausgewählt und der gewünschte Zeitraum eingetragen worden. Mit Hinzufügen wird dieser Teil in die Bedingung übernommen. Das gleiche wird noch für die Abteilung 1 als betreuende Abteilung durchgeführt:
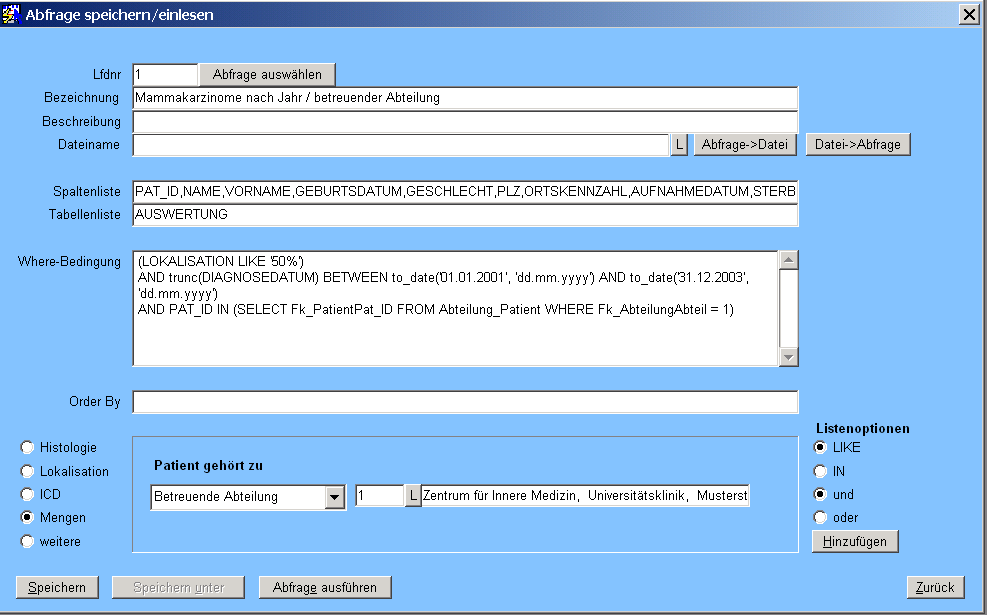
Um die Abfrage später wieder auswählen zu können, wurde sie gespeichert. Sie kann auch in eine Datei exportiert und in einem anderen System wieder eingelesen werden. Auf diese Weise haben die Entwickler die Möglichkeit, kompliziertere Abfragen zu verteilen.
Der zweite Schritt umfaßt nun die Auszählung der gefragten Variablen. Eine erste Übersicht gibt die sogenannte "Standard-Auswertung" mit Angabe von Altersverteilung, Verteilung von Lokalisationen, Histologien, TNM-Kategorien und Stadien. Für die angebene Fragestellung ist dies jedoch nicht ausreichend, da auch Angaben zur operativen Therapie erwartet werden. Es bestehen jetzt folgende Optionen: